Automatic identification of strokes in videos of tennis matches caught my attention recently. I was wondering if I could video my weekend matches and have some method of automatically indexing my strokes. I wanted to see if there was a pattern in the way I played – why did I lose or win? What sequence of shots performed best for me?
1 Introduction
Computer vision and visual recognition has seen significant investment and research over the last few decades. Deep neural networks are able to generalise to such a level where strokes can be identified at a very granular level. Not having much experience with these, the below paper was a nice segway.
https://cs230.stanford.edu/files_winter_2018/projects/6945761.pdf
Action Recognition in Tennis using Deep Neural Networks
The ‘THree dimEnsional TennIs Shots (THETIS) dataset: a sport based human action dataset comprised of the 12 basic tennis shots captured by Kinect’ was used as the test and training data in this paper. Essentially, it has tagged over 1600 videos of tennis strokes (albeit not on a tennis court), across 12 classes e.g forehand, forehand slice, backhand, 2 handed backend, serve etc.



The paper uses a pre-trained convolutional neural network (CNN) layer to generalise visual features from an input – a series of video frames, and provides an output – the class of tennis stroke e.g backhand, forehand etc. A model such as InceptionV3 has been pre-trained using millions of images, a vast dataset that would take forever to train on our local machines. This is what is referred to as transfer learning – we are transferring the learned weights to our own example.
2 Model and Method
For each video, I have chosen only a sample of the frames in the middle of each video to capture the key information of the tennis stroke and making computational time more manageable. After saving the frames of each video, the RGB pixels are normalised using the Inception V3 preprocess_input function, to allow for faster neural network computations. Next, the useful Keras ImageDataGenerator allows for sequential loading in of a large dataset in batches, which is especially useful when running Jupyter on a single CPU. We define two ImageDataGenerators, a training set, with a 10% validation split and our test set. Roughly, a 70-10-20 train, validation, test set is used. As you can see, in absolute terms this results in 20592 training images and 5117 test images across 5 classes: backhand, backhand2hand, forehand, service, smash.
ROWS=480
COLS=600
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.inception_v3 import preprocess_input
from tensorflow import test
train_idg = ImageDataGenerator(preprocessing_function=preprocess_input, validation_split=0.1)
test_idg = ImageDataGenerator(preprocessing_function=preprocess_input)
train_gen = train_idg.flow_from_directory(
'/Users/adamwatson/Desktop/TENNIS/InputFrames/',
target_size=(ROWS, COLS),
)
test_gen = train_idg.flow_from_directory(
'/Users/adamwatson/Desktop/TENNIS/TestFrames/',
target_size=(ROWS, COLS)
)
Found 20592 images belonging to 5 classes. Found 5117 images belonging to 5 classes.
Now our input data is prepared across our 5 classes, let’s define our base Inception model so that we can freeze the pre trained ImageNet layers. Adding to the model sequentially, we add a dropout layer with rate 0.1 to remove neurons at each epoch of our training, forcing learning to spread out across the network. Next, we add a GlobalAveragePooling2D layer to reduce the number of trainable parameters to a more manageable size, which is then fed into a Dense softmax layer to output probabilities of each class. What are we trying to minimise? We define a categorical cross entropy loss function.
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras import optimizers
from tensorflow.keras.layers import Dense, Dropout, Flatten, GlobalAveragePooling2D
# (480,600,3)
input_shape = (ROWS, COLS, 3)
nclass = len(train_gen.class_indices)
base_model = InceptionV3(weights='imagenet',
include_top=False,
input_shape=(ROWS, COLS,3))
# Freeze inception layers (don't train these layers).
base_model.trainable = False
add_model = Sequential()
add_model.add(base_model)
add_model.add(Dropout(rate=0.1))
add_model.add(GlobalAveragePooling2D())
add_model.add(Dense(nclass,
activation='softmax'))
model = add_model
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(learning_rate=0.05,
momentum=0.9),
metrics=['accuracy'])
model.summary()
Model: "sequential_7" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= inception_v3 (Functional) (None, 13, 17, 2048) 21802784 _________________________________________________________________ global_average_pooling2d_7 ( (None, 2048) 0 _________________________________________________________________ dense_7 (Dense) (None, 5) 10245 ================================================================= Total params: 21,813,029 Trainable params: 10,245 Non-trainable params: 21,802,784 _________________________________________________________________
The following combination of parameters were used in training the model:
- 10 Epochs.
- 0.05 Learning Rate.
- 0.1 Dropout Rate
- 128 Batch Size
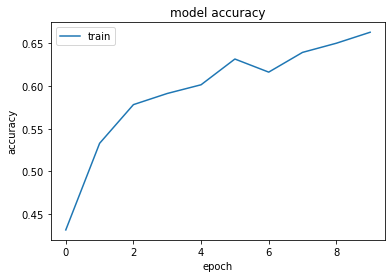
The model was able to achieve an approximate accuracy of 66% across the frames of each video. Whilst this might seem low at first, we then classify each test video by taking the modal class of all test frames belonging to that video. To illustrate an example, the below smash video had classifications split across 14 frames.
| Video | backhand | backhand2hands | forehand | service | smash |
| p9_smash_s3.avi | 5 | 0 | 2 | 1 | 6 |
The class smash has the highest count, thus our model is able to predict a correct class for the correspond video. How does this perform across our full test dataset?
3 Conclusion
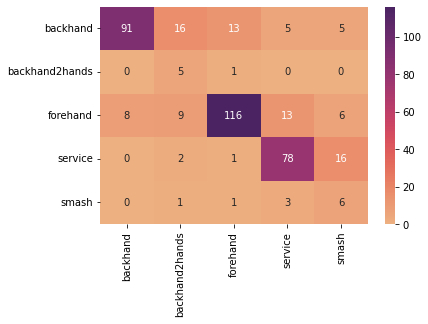
The model achieved around a 79% accuracy score on the video test set, with the below confusion matrix.
| backhand | backhand2hands | forehand | service | smash | |
| Class Performance | 70% | 83% | 76.3% | 80.4% | 54% |
The model looks to perform better on classes which have more videos, which is expected behaviour. Smash strokes tended to be incorrectly marked as a service, due to the similar mechanics of each stroke. Backhand was the lowest score out of the three strokes with the largest datasets: [backhand, forehand, service], and struggled to completely differentiate between single and two handed shots. Service had the highest score out of the three, unsurprisingly struggling to differentiate with the smash strokes.
There are a number of improvements that can be made. First, after reviewing a large sample of the videos, it is clear that the quality of stroke technique is poor, or unrepresentative of a professional’s tennis swing. In some cases, the players weren’t holding the racket correctly. Furthermore, these are all filmed on a basketball court, with people frequently playing basketball behind. This has the effect of muddying the input data. Second, I would look to use the skeletal THETIS dataset, which contains the movement of the skeleton of each player. In tennis, where the arms are in relation to the rest of the body is very important in detecting a tennis stroke. This, I believe, would be a good addition to the input dataset and improve on the training fits. Finally, I would look to incorporate the lines of the tennis court into the model. Relative position of the player is important information in detecting tennis strokes. A right handed player mostly hits a forehand in the right section of the court, for example. The jupyter notebook for this project can be found below: